k8s多租户
背景
企业外部多租需求,为保证安全性和提升资源使用率,需要对每个租户提供一个专用的控制层平面
而原生k8s基于命名空间(Namespace) 机制的多租户是弱多租,没法做到很好的隔离
目前硬多租隔离方案有:
- Kubernetes-sig mutil-tenancy的VirtualCluster
- loft-sh的vCluster
实现原理上大同小异,具体差异可看这里differences between VirtualCluster and vcluster
综合社区兼容性,和完善性,选择VirtualCluster作为分析对象
VirtualCluster
VirtualCluster 代表了一种新架构,可以解决各种 Kubernetes 控制平面隔离挑战。它通过为每个租户提供集群视图来扩展现有的基于命名空间的 Kubernetes 多租户模型。 VirtualCluster 完全利用了 Kubernetes 的可扩展性并保留了完整的 API 兼容性。使用VirtualCluster,每个租户会被分配一个专用的租户控制层,租户可以在租户控制平面中创建集群范围资源,例如命名空间和 CRD,而不会影响其他人,因此,由于共享一个 apiserver 导致的大部分隔离问题都消失了。管理和维护实际物理节点的 Kubernetes 集群称为super cluster,现在成为 Pod 资源提供者,至于数据层的隔离则是用安全沙箱容器,例如kata。
VirtualCluster由如下组件组成:
- vc-manager:引入了新的 CRD VirtualCluster 来对租户控制平面进行建模。 vc-manager 管理每个 VirtualCluster 自定义资源的生命周期。根据规范,它要么在本地 K8s 集群中创建控制平面 Pod,要么在提供有效 kubeconfig 的情况下导入现有集群。
- syncer:一个集中控制器,将 Pod 供应所需的 API 对象,从每个租户控制平面填充到超级集群,并双向同步对象状态。它还定期扫描同步对象,以确保租户控制平面和超级集群之间的状态一致。
- vn-agent:一个节点守护进程,它将所有租户 kubelet API 请求代理到在节点中运行的 kubelet 进程。它确保每个租户只能访问节点中自己的 Pod。
局限性
理想情况下,租户在大多数情况下不应该知道super cluster的存在。比较租户控制平面和普通 Kubernetes 集群,仍然存在一些明显的差异。
- 在租户控制平面中,节点对象只有在租户 Pod 被创建后才会出现。super cluster节点拓扑没有完全暴露在租户控制平面中。这意味着 VirtualCluster 不支持租户控制平面中的类似 DaemonSet 的工作负载。目前,如果新创建的租户 Pod 的
nodename已在spec中设置,则syncer controller会拒绝它。 - syncer controller管理租户控制平面中node对象的生命周期,但它不会更新node lease对象以减少网络流量。因此,建议将租户控制平面节点控制器 –node-monitor-grace-period 参数增加到更大的值(>60 秒)
- Coredns 感知不到租户。因此,如果需要 DNS,租户应在租户控制平面中安装 coredns。应该使用名称 kube-dns 在 kube-system 命名空间中创建 DNS 服务。然后syncer controller可以在super cluster中识别 DNS service的cluster IP ,并将其注入任何
Pod spec.dnsConfig。 - 租户service spec中的cluster IP 字段是一个虚假值。如果任何租户控制器需要在super cluster节点中生效实际的cluster IP,则需要进行特殊处理。syncer将使用
transparent.tenancy.x-k8s.io/clusterIP作为key,在租户services对象的annotations中回填super cluster中使用的cluster IP。然后,解决方法通常是在控制器中进行简单的代码更改。本文档显示了 coredns 的示例。 - VirtualCluster 不支持租户 PersistentVolumes。所有的 PV 和 Storageclass 都由super cluster提供。
架构原理
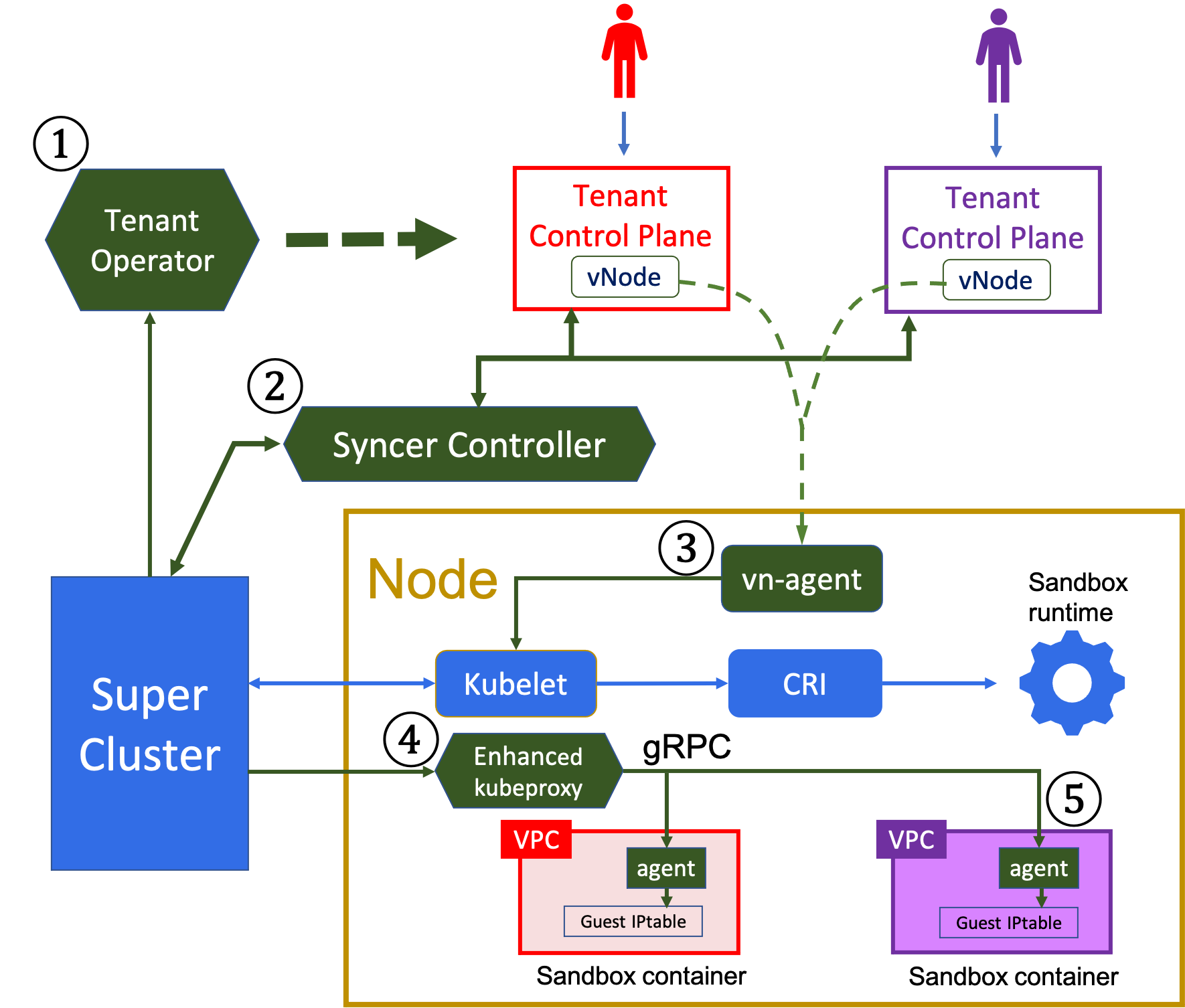
图1
1. Tenant Operator
VirtualCluster CRD,简称VC, 定义为描述租户控制平面规范 比如apiserver版本,资源配置等。VC对象由Super Cluster管理员管理。这个租户Operator调谐(reconcile) VC 对象的状态,无论何时它们被更改,以处理租户控制平面的生命周期事件。
请注意,租户控制平面不需要调度器,因为 Pod 调度是在super cluster中完成的。
VC目前支持本地模式和云模式进行配置租户控制平面。在云模式下,租户operator利用阿里云ACK或AWS EKS等公有云服务 ,用于管理控制平面组件。它还存储了集群访问凭证,super cluster中每个租户控制平面的 kubeconf ig,以便syncer控制器可以从super cluster访问所有租户控制平面。不允许租户访问超级集群。
2. Syncer controller
syncer只填充在Pod provision中使用的租户对象,例如:命名空间(Namespaces),Pods,Services,Secrets等等。对于super cluster,不包括所有其他控制或扩展对象。
请注意,所有对同步对象的读请求均由租户apiservers提供服务,从而缓解super cluster的压力,相比所有租户都直接访问super cluster的场景。
在Kubernetes中,任何命名空间作用域对象的全称,例如namespace/objectname,必须唯一。
syncer为每一个同步的租户命名空间(Namespace)都会添加一个前缀,避免名称冲突。
前缀是将VC 的对象所有者名称和对象的 UID 的哈希值,做一个简短的连接
。同步器的作用不仅仅是复制对象。
3. Virtual Node agent
在 Kubernetes 中,kubelet 只能将自己注册到一个 apiserver,即 Virtual Cluster 中的Super Cluster。因此,常用的 kubelet API,例如 log 和exec 对租户不起作用,因为租户 apiserver 不能直接访问kubelet。实现了一个虚拟节点代理(vn-agent) 解决这个问题,它运行在每个节点上代理租户的 kubelet API 请求。更具体地说,一旦
在super cluster中调度了一个 Pod,syncer将创建租户 apiserver 中的虚拟节点对象。为了拦截kubelet API 请求,虚拟节点指向物理节点中的 vn-agent而不是 kubelet 。当代理请求时,vn-agent 需要从 HTTPS请求 中识别租户,因为租户 Pod 在super cluster中的Namespace与租户控制平面的不同。发送请求的租户可以是通过将其 TLS 证书的哈希值与保存在每个 VC 对象中的哈希值作对比来识别。之后可以计算出它在super cluster中使用的命名空间(Namespace)前缀
4. 增强型kubeproxy
在Kubernetes中,cluster IP类型的Services,定义了集群内访问一组端点的路由策略(即访问Pods),路由策略由一个 kubeproxy 守护进程实施,它会在Service endpoints发生变化时,更新主机的IPtables。当容器连到一个VPC(virtual private cloud)网络时,这个机制就被破坏了。因为网络流量可通过一个vendor-specific network interface绕过主机网络协议栈(network stack)。为了在这样的环境下启用cluster IP类型的Services,通过允许直接注入或者更新每个Kata容器的guest OS中的网络路由规则来增强kubeproxy。更具体的说,允许在guest OS中的Kata agent开启一个与kubeproxy的安全的gRPC连接,通过它可以将服务路由规则应用于guest OS的 IPtable
kubeproxy 的改动是适度的。它需要监视 Pod 创建事件,并且和 Pod init容器 配合。Pod init容器先于任何工作负载(workload)容器运行,检查 IPtable 更新进度,确保在工作负载(workload)容器启动之前注入路由规则
实验数据
实验环境:1.18 Kubernetes集群,1 Master + 2 woker Node
为了测量syncer controller的资源使用,避免其他组件潜在的干扰,在其中一个worker node部署syncer controller,在另一个work node部署租户控制平面(tenant control planes)。每个租户控制平面使用一个专用的etcd。所有的控制平面使用一个高速的virtual switch连到同一个VPC。由于资源限制,我们在super cluster安装了100个virtual kubelets,来模拟一个拥有100个节点,运行大量Pods的集群。请注意注意实验中Pod的创建延迟由于使用了virtual kubelet,并没有把拉取镜像和创建容器的时间包含在内。
选取Pod端到端创建时间作为主要性能指标主要有如下原因:
- 当VirtualCluster在高负载的情况下,syncer引入的队列延迟是主要的性能问题
- Pod对象,作为Kubernetes主要的对象,可能是最复杂的模式,并且还发明很多对象来为它服务。操作pod对象的性能将会有很高的代表性
- Pod创建触发了一个复杂的工作流程,包括其他主要的Kubernetes组件,像scheduler和kubelet。它正处于应用部署的关键路径。因此它的性能经常被强调
当VirtualCluster部署正常的load,syncer每秒的请求会有1或2毫秒延迟,这在典型的Kubernetes用例中,是不值得一提的。开发了一个可以同时在所有租户控制平面创建大量Pod的负载生成器(load generator)来给系统做压测。在super cluster,每一个virtual kubelet运行一个模拟pod的提供者(mock Pod provider),标记所有Pod调度到virtual kubelet,并且立即设置为running的状态。Pod创建时间通过计算租户pod的创建时间戳,和租户里Pod condition被更新为ready的时间戳之差,包括所有队列延迟和有syncer产生的对象同步的开销。通过负载生成器(load generator)直接发送所有请求到super cluster生成一些基线用例,来做对比。基线中Pod的创建时间通过Pod创建时间戳和Pod的condition状态更新为ready的时间戳来计算。
1. Syncer controller对延迟的影响
可能影响Syncer延迟方面性能的三个因素。它们是创建的 Pod 数、租户数和下行工作线程数。通过改变每个因素的数量得到了十二个案例,结果如图 2 所示。在每个用例中,每个租户中创建的 Pod 数量是相等的。
对于基线用例,负载生成器使用与租户数量相同的线程数直接将Pod提交到超级集群。 将 Pod 创建时间直方图与基线案例的直方图进行比较,结果为如图2所示。集中的直方图表示性能稳定,而平坦的直方图表示高性能变化。
图 2 显示使用 VirtualCluster 不会显着延长 Pod 创建时间。大多数操作的延迟都在基线延迟范围内。
例如,当使用 100 个租户和 20 个工作线程时,在创建 1250、2500、5000 和 10000 个 Pod 时,TP99(99% 百分位延迟)为 3秒(基线为 1秒)、4秒(基线为 2秒)、8秒(基线为8秒)、14秒(基线为8秒)。
由基线用例在创建大量 Pod 时表现出明显的性能变化。可以发现super cluster的可扩展性瓶颈是调度器。默认的 Kubernetes 调度器只有一个队列,它按顺序调度 Pod。因此,在实验中看到当每秒几百个 Pod 创建时,调度器吞吐量达到峰值。在高 Pod 流失率下,调度队列延迟会减慢 Pod 创建过程,这也解释了另一个观察结果,即增加下行工作线程的数量根本没有帮助减少延迟。花费在同步器向下调谐循环(reconcile loop)上的时间是微不足道的。使用20个工作线程足以推动super cluster达到调度吞吐量的上限。但是,上行工作线程的数量确实会影响延迟(图中未显示),因为租户控制平面在处理对象状态更新方面没有瓶颈。因此,我们在同步器中设置了较高的默认向上工作线程数为100和较低的默认值为20向下工作线程。在图 2 中,我们还可以观察到租户数量不会影响创建相同数量 Pod 的延迟。
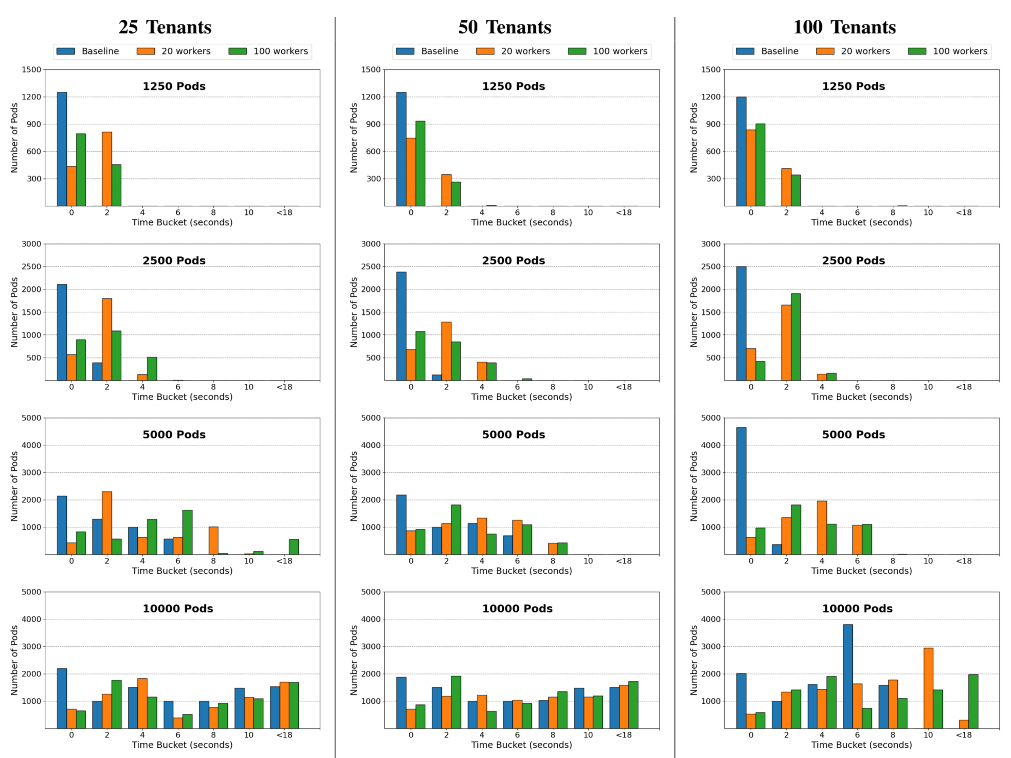
图2
2. Syncer controller对吞吐量的影响
通过计算每秒创建Pod数量来评估VirtualCluster吞吐量,结果如图3所示。
从图 3(a) 中,当创建相同数量的 Pod(10000Pods), 可以看到租户数量不影响吞吐量。 VirtualCluster 引入了约 21% 的恒定吞吐量下降。由于syncer中的一些关键部分(例如工作队列入队或出队)无法并行化,因此预估吞吐量较低。syncer中的锁竞争可能也会降低吞吐量。
图 3(b) 显示,当租户数固定(100个租户),吞吐量大致为VirtualCluster 的常数,但随着 Pod 数量的增加,基线用例反而会变得更低,最大吞吐量下降约为 34%。请注意,添加更多syncer可能会通过减少每个同步器锁竞争来提高整体吞吐量。但是,由于以下几个原因,它不是可取的:
1)无论租户数量和Pod数量如何,使用一个同步器仍然可以实现可持续的吞吐量;
2)与控制平面吞吐量相比,从租户的角度来看,操作延迟更为重要。
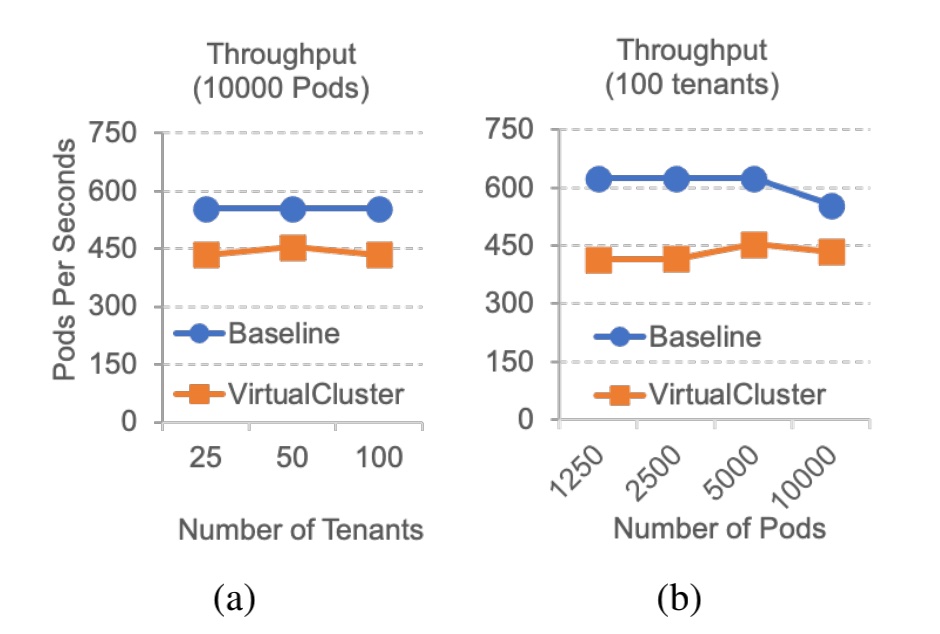
图3
3.Syncer controller的开销
Syncer的可用计算资源会在它繁忙时影响其性能。实验中,没有为syncer设置资源限制。图 4 显示了实验中同步器控制器的 CPU 和内存使用情况。正如预期的那样,随着 Pod 数量的增加,资源使用量几乎呈线性增加。可以通过计算累积的 CPU 时间除以进程挂钟时间来估计消耗的 CPU 的平均数量。比如在一万个Pod的情况下,syncer在实验过程中大致消耗了$\frac{138}{23}$个CPU,也就是6个CPU,远远超出了正常情况下的要求。通常建议syncer的 CPU 限制为1到2个 CPU。在一万个 Pod 的情况下,syncer的峰值内存使用量约为 1.2GB。峰值内存增长率大约为每个 Pod 40KB,这是通过计算曲线的比率来估计的。syncer中的主要内存消耗是 Informer 缓存。一个租户对象在syncer中至少有两个副本,一个在租户控制平面的informer缓存中,另一个在超级集群(super cluster)informer缓存中。syncer工作队列在增长时也会消耗内存,但队列的请求的大小通常很小(几个字节),并且队列不会因为重复数据删除而无限增长。 我们还检查了syncer重启性能,当100 个租户控制平面10000个Pods时,它花费少于21秒初始化所有 Informer 缓存,这是相当快的,因为syncer重启很少见。此外,我们还测量了syncer中周期性扫描线程的开销。并行扫描线程数等于租户数,扫描间隔设置为一分钟。发现平均完成扫描 10000 个 Pod 的时间不到两秒钟。
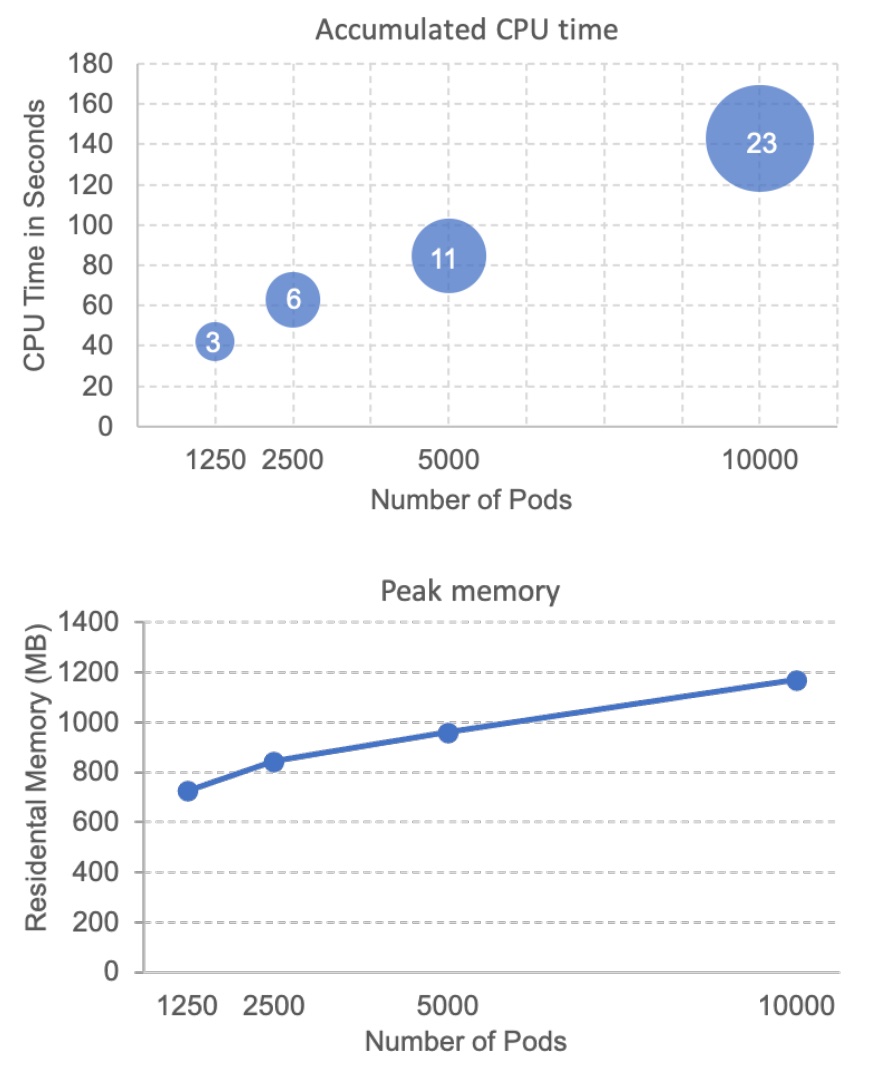
图4
References
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!