kubernetes万级规模高可用
当集群节点超过5000时
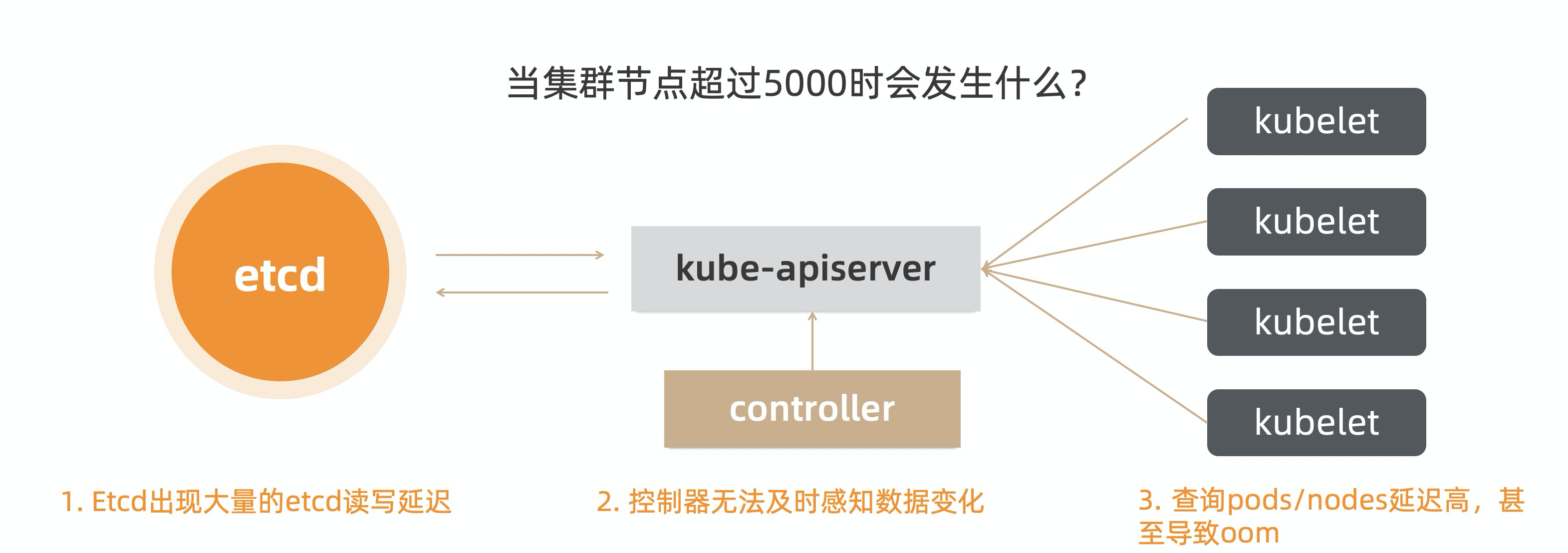
问题
- etcd 出现大量的读写延迟。
- kube-apiserver 查询 pods/nodes 延时很高,甚至导致 etcd oom。
- 控制器无法及时感知数据变化,如出现 watch 数据延迟。
解决方案:
100 节点增长到 4 千节点:
- 从 apiserver 客户端的角度优先访问本地 cache,在客户端去做负载均衡
- apiserver 服务端主要做了 watch 优化和 cache 索引优化
- 在 etcd 内核上利用并发读提升单 etcd 集群读处理能力,基于 hashmap 的 freelist 管理新算法提高 etcd 存储上限,基于 raft learner 技术来提高多备能力
4 千节点增长到 8 千节点:
- qps 限流管理和容量管理优化
- etcd 单资源对象存储拆分
- 组件规范全生命周期落地通过客户端的规范约束降低对 apiserver 的压力和以及穿透到 etcd 的压力等等
8 千节点增长到上万节点:
- etcdcompact 算法优化
- etcd 单节点多 multiboltdb 的架构优化
- apiserver 的服务端数据压缩
- 通过组件治理降低 etcd 写放大等
- 同时开始打造常态化的压测服务能力
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!